ARCHIVED CONTENT
You are viewing ARCHIVED CONTENT released online between 1 April 2010 and 24 August 2018 or content that has been selectively archived and is no longer active. Content in this archive is NOT UPDATED, and links may not function.By William Webber
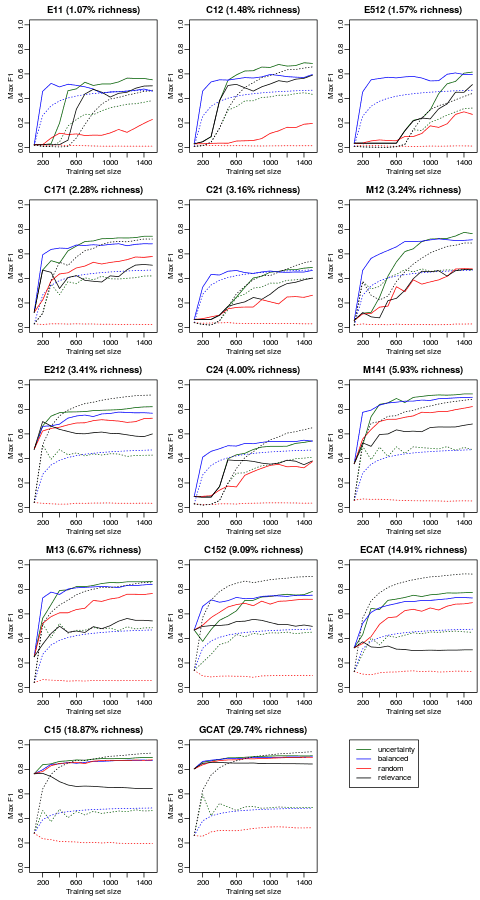
The problem with agreeing to teach is that you have less time for blogging, and the problem with a hiatus in blogging is that the topic you were in the middle of discussing gets overtaken by questions of more immediate interest. I hope to return to the question of simulating assessor error in a later post, but first I want to talk about an issue that is attracting attention at the moment: how to select documents for training a predictive coding system.
The catalyst for this current interest is “Evaluation of Machine Learning Protocols for Technology Assisted Review in Electronic Discovery”, recently presented at SIGIR by Gord Cormack and Maura Grossman. In fact, there are two questions, somewhat conflated in Maura and Gord’s paper. The first is, should the initial seed set of training examples be selected by random or by judgmental sampling (for instance, based on a keyword query)? The second is, having seeded the training cycle, how should subsequent training examples be selected? I’ll tackle the second issue here; I hope to return to the first in a later post.
Read the original article at: Random vs active selection of training examples in e-discovery




















