ARCHIVED CONTENT
You are viewing ARCHIVED CONTENT released online between 1 April 2010 and 24 August 2018 or content that has been selectively archived and is no longer active. Content in this archive is NOT UPDATED, and links may not function.By John Tredennick
This past weekend I received an advance copy of a new research paper prepared by Gordon Cormack and Maura Grossman, “Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery.” They have posted an author’s copy here.
The study attempted to answer one of the more important questions surrounding TAR methodology:
Should training documents be selected at random, or should they be selected using one or more non-random methods, such as keyword search or active learning?
Their conclusion was unequivocal:
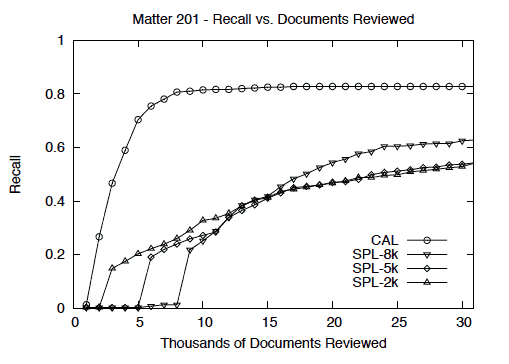
The results show that entirely non-random training methods, in which the initial training documents are selected using a simple keyword search, and subsequent training documents are selected by active learning, require substantially and significantly less human review effort (P < 0.01) to achieve any given level of recall, than passive learning, in which the machine-learning algorithm plays no role in the selection of training documents.
Among passive-learning methods, significantly less human review effort (P < 0.01) is required when keywords are used instead of random sampling to select the initial training documents. Among active-learning methods, continuous active learning with relevance feedback yields generally superior results to simple active learning with uncertainty sampling, while avoiding the vexing issue of “stabilization” – determining when training is adequate, and therefore may stop.




















