ARCHIVED CONTENT
You are viewing ARCHIVED CONTENT released online between 1 April 2010 and 24 August 2018 or content that has been selectively archived and is no longer active. Content in this archive is NOT UPDATED, and links may not function.
By Bill Dimm
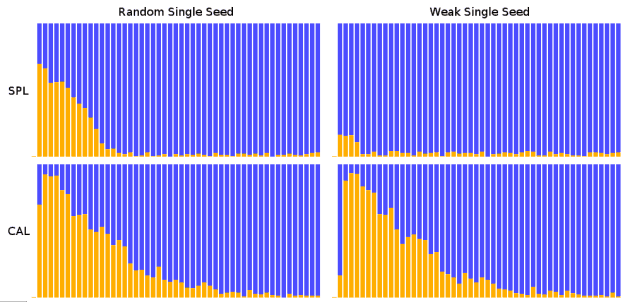
This article shows that it is often possible to find the vast majority of the relevant documents in a collection by starting with a single relevant seed document and using continuous active learning (CAL). This has important implications for making review efficient, making predictive coding practical for smaller document sets, and putting eyes on relevant documents as early as possible, perhaps leading to settlement before too much is spent on document review. It also means that meticulously constructing seed sets and arguing about them with opposing counsel is probably a waste of time if CAL is used.
Read the original article at: The Single Seed Hypothesis




















