
|
|
An updated article by Rob Robinson
Framing the Automation of Discovery
One of the biggest challenges facing information, business, and legal professionals is the ability to cohesively consider the elements of data discovery and legal discovery within a technology framework that is comprehensive enough to address critical discovery tasks throughout information and legal lifecycles yet concise enough to be realistically approached from an integration and automation perspective.
This challenge becomes even more daunting when one moves from considering discovery-related technology tasks and begins to look at how these tasks help drive business and legal decision making. In fact, one only has to look as far as the results of the Information Governance Initiative’s State of the Industry Report (April 2018) to see how many different and discovery-dependent information disciplines are considered as part of the information governance technology ecosystem to understand the need for a concise way to frame the integration of automation of task, processes, and technologies contributing to the discovery of data.
22 Information Disciplines Highlighted as Part of the Information Governance Ecosystem1
- Records and Information Management – 94%
- Information Security and Protection – 93%
- Compliance – 88%
- Data Governance – 88%
- Risk Management – 86%
- eDiscovery – 84%
- Privacy – 84%
- Data Storage and Archiving – 83%
- Legal – 78%
- Knowledge Management – 67%
- Business Operations and Management – 67%
- Audit – 65%
- IT Management – 64%
- Digital Curation/Stewardship – 64%
- Analytics – 63%
- Enterprise Architecture – 63%
- Master Data Management – 63%
- Big Data – 63%
- Business Intelligence – 59%
- Informatics – 52%
- Data Science – 52%
- Finance – 42%
- All of the Above – 38%
While information governance is only one of many data disciplines dependent on discovery-related technologies, it does provide an excellent example of the complexity of addressing discovery-related tasks from a perspective of task and process automation.
From Complex Models to Concise Frameworks
Today, multiple published models ranging from the EDRM’s Information Governance Reference Model (IGRM) and ARMA’s Information Governance Maturity Model to NIST’s Framework for Improving Critical Infrastructure Cybersecurity exist to help information professionals address domain-specific areas requiring the need for discovery technology. These models also help users in translating insight into intelligence that informs data-driven decisions. However, there appears to be a need for a concise technology framework that might be used to help translate an understanding of extensive discovery needs into a simplified discovery workflow.
Said in a different way, it seems reasonable that a planning framework addressing the core tasks of data and legal discovery might be beneficial in helping technology providers develop automated discovery solutions that address data from the point of initial creation to the point of defensible destruction. Such a framework might also serve to help explain to potential users the relationship between tasks, functions, and automation in data and legal discovery.
Provided below for consideration and use is one example of a strategic framework that may be beneficial in helping technology providers as they develop, integrate, automate and message data and legal discovery offerings.
A Strategic Framework for Data and Legal Discovery
In developing a strategic framework for data and legal discovery, it is first important to define several key elements and drivers included in the framework. Seven of these elements and drivers are defined below.
- Data Discovery is the exploration of patterns and trends within unstructured data with the objective of uncovering insight and driving action.2
- Electronic Discovery (Legal Discovery) is the process of identifying, preserving, collecting, processing, searching, reviewing and producing electronically stored information that may be relevant to a civil, criminal, or regulatory matter.3
- Discovery Automation Technology is technology that decreases the requirement for human intervention in the completion of discovery tasks and processes.4
- Information Governance (IG) is the specification of decision rights and an accountability framework to ensure appropriate behavior in the valuation, creation, storage, use, archiving and deletion of information. It includes the processes, roles and policies, standards and metrics that ensure the effective and efficient use of information in enabling an organization to achieve its goals.5
- Unstructured Data is content that does not conform to a specific, pre-defined data model. It tends to be the human-generated and people-oriented content that does not fit neatly into database tables.6
- Insight is the understanding of cause and effect based on the identification of relationships and behaviors within a model, context or scenario.7 As defined by Graham Wallas, the four stages of insight include preparation, incubation, flash of illumination and verification. 8
- Intelligence is the ability to acquire and apply knowledge and skills.9
By taking these definitions and viewing them through the lens of a general workflow, one can construct and align a concise discovery automation model that can help frame key discovery tasks and processes.
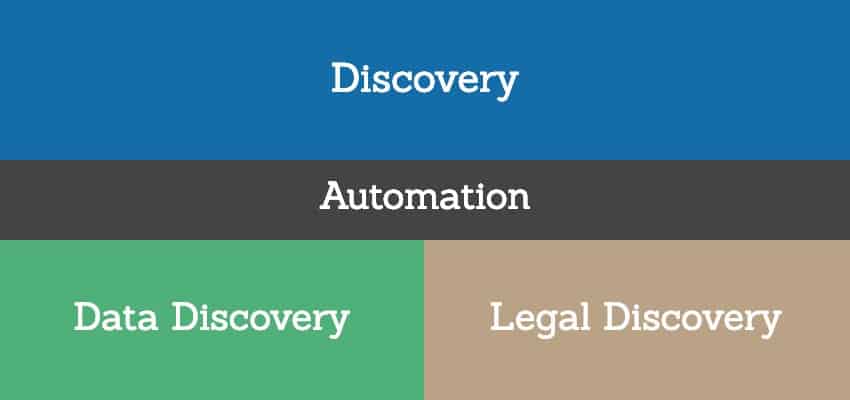
Figure 1: Two Components of Discovery
Data Discovery: Insight from Data Creation to Collection
From this high-level framework, one can then add a layer of critical automation processes and tasks. The key automation processes and tasks for data discovery within the concise discovery automation model include:
Automation of Interrogation and Indexing
- Automated interrogation allows organizations to find unstructured data that resides on endpoint computers and servers.
- Automated indexing provides customers a systematic arrangement of data type, location, and content that can be searched in a concise and cohesive manner.
- The combination of continuous and automated interrogation and indexing allows organizations to gain insight (insight analysis) immediately and accurately from all unstructured data from the moment of its creation.
Once implemented, this capability helps users answer the important and often perplexing question of where to start data exploration and discovery efforts.
Automation of File Preservation and Collection
- File preservation automation allows users to establish a rules-based identification of files that may need to be preserved for audits, investigations, or litigation. This capability also prepares those files for collection and use in further assessments and evaluations.
- Collection automation takes files identified for preservation and collects them into a user designated repository. This preservation repository of collected files can then be assessed and evaluated to provide additional insight into data.
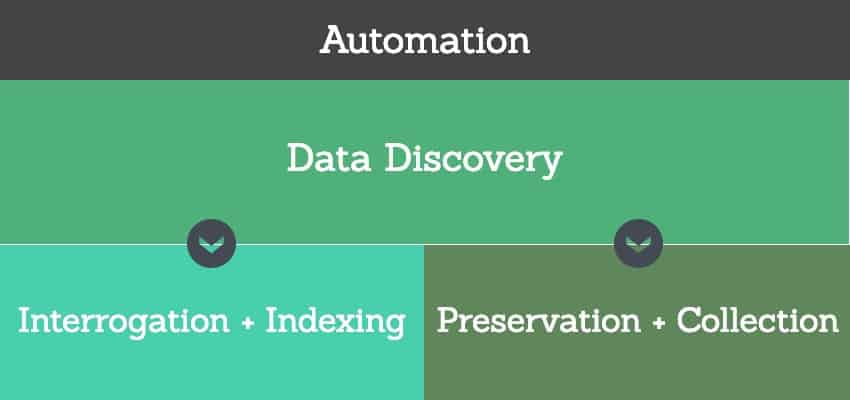
Figure 2: Two Components of Data Discovery
Once executed, these tasks help users answer the question of how to transition from insight and preservation analysis into formal document reviews.
Legal Discovery: Intelligence from eDiscovery to Defensible Disposition
The key automation processes and tasks for legal discovery within the concise discovery automation model include:
Automation of Ingestion and Processing
Ingestion and processing automation allow users to upload data into a secure online repository in a private and protected cloud environment and have that data automatically converted into a usable format for review.
Automation of Review and Production
- Review automation allows users to utilize advanced analytics and technology-assisted review to assess, review, and analyze data.
- Production automation gives users the ability to create precision productions and privilege logs that are exportable into almost any form.
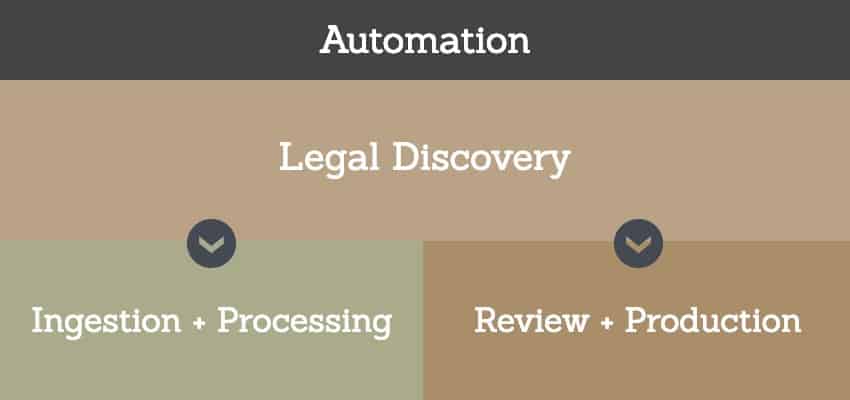
Figure 3: Two Components of Legal Discovery
Once completed, these tasks provide intelligence that helps users comprehensively answer policy, regulatory, or legal questions that typically drive audits, investigations, and litigation.
Reprise
The combined discovery framework takes the overall process of discovery, breaks it down into a data discovery component and a legal discovery component, aligns these components with insight and intelligence, and then highlights four key processes and eight key tasks that appear to be important in the discovery process across the lifecycle of information and litigation.
Discovery Automation Technology Focus
- Data Discovery: Insight from Data Creation to Collection
- Legal Discovery: Intelligence from eDiscovery to Defensible Disposition
Discovery Processes
- Automation of Interrogation and Indexing (Data Discovery)
- Automation of File Preservation and Collection (Data Discovery)
- Automation of Ingestion and Processing (Legal Discovery)
- Automation of Review and Production (Legal Discovery)
Discovery Tasks
- Interrogation (Data Discovery | Automation of Interrogation and Indexing)
- Indexing (Data Discovery | Automation of Interrogation and Indexing)
- Preservation (Data Discovery | Automation of Preservation and Collection)
- Collection (Data Discovery | Automation of Preservation and Collection)
- Ingestion (Legal Discovery | Automation of Ingestion and Processing)
- Processing (Legal Discovery | Automation of Ingestion and Processing)
- Review (Legal Discovery | Automation of Review and Production)
- Production (Legal Discovery | Automation of Review and Production)
Additionally, this non-all inclusive process and level framework may be beneficial for expanding thought and action in areas related to the automation of data and legal discovery processes and tasks. Examples of this expanded thought include but are not limited to:
- The addition of a subtask of auto-classification to the task of indexing.
- The addition of a subtask of in-place record removal to the task of collection.
- The addition of a subtask of legal hold to the task of file preservation.
- The addition of a subtask of technology-assisted review to the task of review.
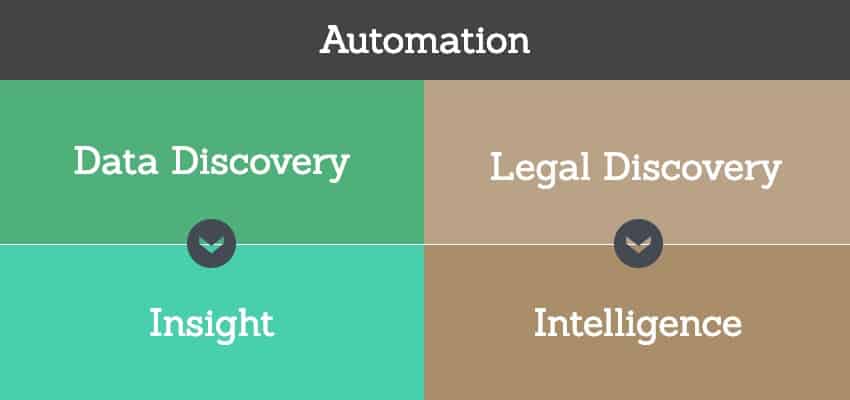
Figure 4: Two Drivers of Automation: The Need for Insight and The Need for Intelligence
While frameworks such as this framework for discovery automation are helpful in developing efficient and understandable offerings and messaging, they are, by design, not comprehensive or complete. However, frameworks such as this one may provide substantial value to those developing solutions or creating messaging to explain solutions as they provide sequential context and positional awareness for the core elements, processes, and tasks within the framework and help frame the translation of data discovery into insight and legal discovery into intelligence through the application of task and process automation.
References
1 Information Governance Initiative (IGI). (2018, April 26). What Technologies Are Part of the IG Products Market? – Information Governance Initiative. Retrieved from https://iginitiative.com/resources/the-state-of-information-governance-report-volume-iii/.
2 All, A. (2014, September 18). Data Discovery Is Changing Business Intelligence – Enterprise Apps Today. Retrieved from http://www.enterpriseappstoday.com/business-intelligence/data-discovery-is-changing-business-intelligence.html.
3 Grossman, M., & Cormack, G. (2013). The Grossman-Cormack Glossary of Technology-Assisted Review. Federal Courts Law Review, 7(1). Retrieved from http://www.fclr.org/fclr/articles/html/2010/grossman.pdf
4 Robinson, W. (2016, June 6). What is eDiscovery Automation? A Short Definitional Framework. Retrieved from http://www.complexdiscovery.com/info/2016/06/06/what-is-ediscovery-automation/
5 Gartner IT Glossary. (n.d). Retrieved from http://blogs.gartner.com/it-glossary/information-governance/
6 Stewart, D. (2013, May 1). Big Content: The Unstructured Side of Big Data – Darin Stewart. Retrieved from http://blogs.gartner.com/darin-stewart/2013/05/01/big-content-the-unstructured-side-of-big-data/
7 Wikipedia. (n.d.). Insight – Wikipedia, the free encyclopedia. Retrieved October 8, 2016, from https://en.wikipedia.org/wiki/Insight
8 Klein, G. (2013, June 12). The Different Forms of Insight | Psychology Today. Retrieved from https://www.psychologytoday.com/blog/seeing-what-others-dont/201306/the-different-forms-insight
9 Intelligence – Definition of Intelligence in English | Oxford Dictionaries. (n.d.). Retrieved from https://en.oxforddictionaries.com/definition/intelligence
Additional Reading
- Considering Fourth Generation eDiscovery Technology Offerings: Two Approaches (Part One)
- Consideration Fourth Generation eDiscovery Technology Offerings: Two Approaches (Part Two)
Source: ComplexDiscovery
























